Schéma bilan de la synthèse des protéines



Schéma bilan de la synthèse des protéines
On sait qu’un gène code pour une protéine. Il s’agit de préciser les modalités de ce codage.
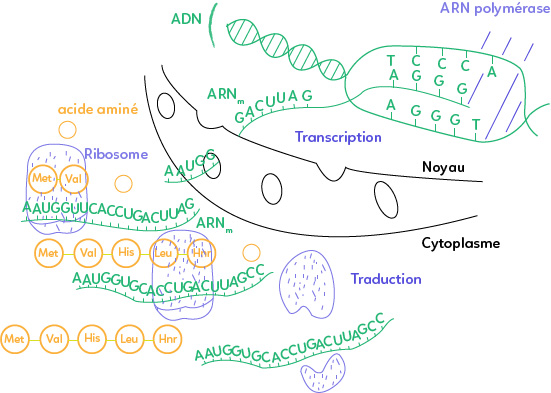
I. Transcription de l’ARN messager
Tout commence dans le noyau, avec un gène, qui est une portion de la molécule d’ADN. Le problème est que cet ADN est enfermé dans le noyau. Il ne peut pas en sortir par les pores nucléaires car il est trop gros. D’où la nécessité, sans finalisme, de synthétiser un ARN messager qui est une molécule intermédiaire entre le noyau et le cytoplasme.
Cet ARN messager (ARNm) est transcrit à partir d’un brin transcrit de l’ADN via une ARN polymérase. On remarque que l’ARNm est complémentaire du brin transcrit de l’ADN. L’autre brin de l’ADN qui n’est pas transcrit est appelé « brin non transcrit » ou « brin codant ». En effet, si l’on regarde la séquence des nucléotides du brin codant, elle est exactement la même que celle de l’ARNm, à une différence près : si on a un T (thymine) sur le brin codant, on a un U (uracile) sur l’ARNm.
II. Traduction en protéines
Une fois la transcription de l’ARNm réalisée, celui-ci sort dans le cytoplasme où il est traduit (traduction) en protéine ou polypeptides. Une fois dans le cytoplasme, l’ARNm est lu par un ribosome (petite tête de lecture). Il lit six nucléotides consécutifs. Trois nucléotides (= codon) codent pour un acide aminé.
Ici, le premier codon qui est lu (AUG) correspond à l’acide aminé « méthionine » (Met). Celui-ci arrive par l’intermédiaire d’un ARN de transfert (non au programme). Le deuxième codon lu est GUG. D’après le tableau du code génétique, GUG code pour la valine (Val). Le ribosome arrive donc sur l’ARNm et se déplace de trois en trois le long de celui-ci. Au fur et à mesure, il se déplace vers la droite et on a la synthèse d’une protéine ou polypeptides.
Une protéine est une séquence ordonnée d’acides aminés et l’autre nom pour « acide aminé » est « peptide ». C’est pour cela qu’on parle aussi de polypeptides.
Le ribosome avance sur l’ARNm et arrive à un endroit donné sur un codon appelé « codon-stop » (voir tableau du code génétique). Ici, le codon-stop est le codon UAG. Un codon-stop est l’un des trois codons qui marquent la fin de la traduction d’un gène en protéine. Quand le ribosome arrive sur le codon-stop UAG, la traduction se termine. Le ribosome s’en va (ses deux sous unités). L’ARNm est détruit et on obtient une protéine. Les peptides sont liés entre eux par des liaisons peptidiques.
En plus (limite hors programme)
Dans le noyau, l’ARNm subit un certain nombre de maturations. Ces maturations permettent de faire en sorte qu’un gène code pour plusieurs protéines.